Overview of HiFace
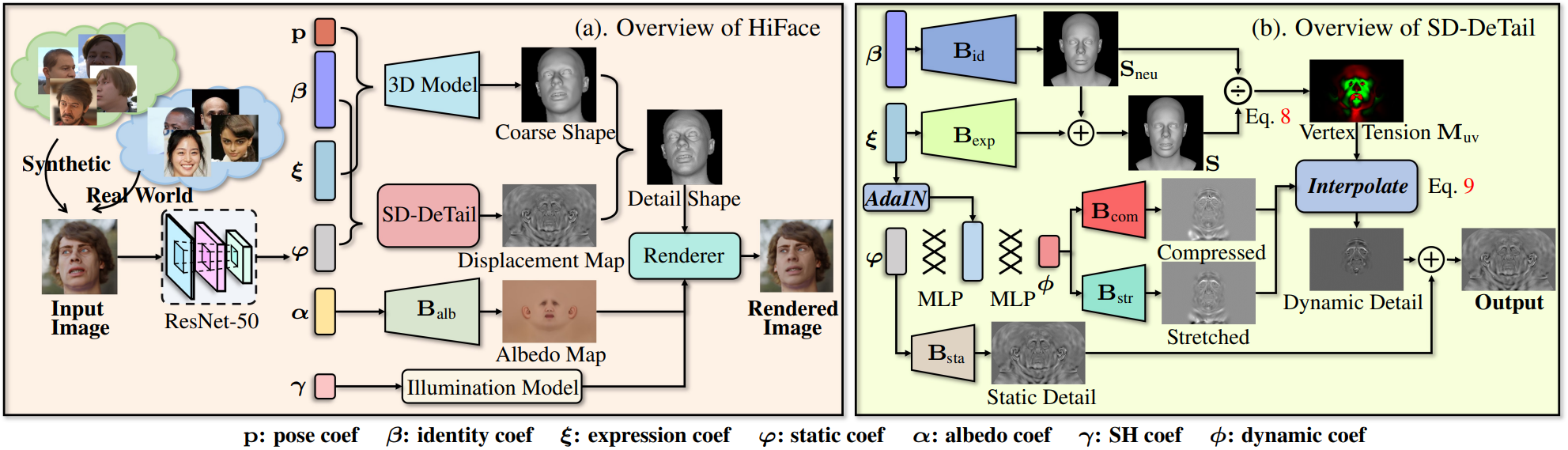
Illustration of HiFace. (a). The learning architecture of HiFace. Given a monocular image, we regress its shape and detail coefficients to synthesize a realistic 3D face, and leverage a differentiable renderer to train the whole model end-to-end from synthetic and real-world images. (b). The pipeline of Static and Dynamic Decoupling for DeTail Reconstruction (SD-DeTail). We explicitly decouple the static and dynamic factors to synthesize realistic and animatable details. Given the shape and static coefficients, we regress the static and dynamic details through displacement bases and interpolate them into the final details through vertex tension.